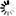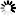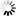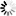
This will start at the specified URL and recursively download pages up to 3 links away from the original page, but only pages which are in the directory of the URL you specified (emacstips/) or one of its subdirectories.
wget will also rewrite the links in the pages it downloaded to make your downloaded copy a useful local copy, and it will download all page prerequisites (e.g. images, stylesheets, and the like).
The last two options -nH --cut-dirs=1 control where wget places the output. If you omitted those two options, wget would, for example, download http://web.psung.name/emacstips/index.html and place it under a subdirectory web.psung.name/emacstips of the current directory. With only -nH ("no host directory") wget would write that same file to a subdirectory emacstips. And with both options wget would write that same file to the current directory. In general, if you want to reduce the number of extraneous directories created, change cut-dirs to be the number of leading directories in your URL.
wget will also rewrite the links in the pages it downloaded to make your downloaded copy a useful local copy, and it will download all page prerequisites (e.g. images, stylesheets, and the like).
The last two options -nH --cut-dirs=1 control where wget places the output. If you omitted those two options, wget would, for example, download http://web.psung.name/emacstips/index.html and place it under a subdirectory web.psung.name/emacstips of the current directory. With only -nH ("no host directory") wget would write that same file to a subdirectory emacstips. And with both options wget would write that same file to the current directory. In general, if you want to reduce the number of extraneous directories created, change cut-dirs to be the number of leading directories in your URL.
Expand |
Embed | Plain Text
Copy this code and paste it in your HTML
URL: http://psung.blogspot.com/2008/06/using-wget-or-curl-to-download-web.html
Comments
 Subscribe to comments
Subscribe to comments