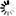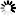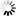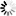
アルゴリズムコンテストã®å‹‰å¼·ä¼šã§ç´¹ä»‹ã—ãŸGoogle App Engineã§å‹•ãpythonコードã§ã™
Djangoフレームワークをå‰æã«ã—ã¦ã„ã¾ã™ã€‚
ã‚ã¾ã‚Šã‚³ãƒ¼ãƒ‰ã¨ã—ã¦ã¯å‚考ã«ãªã‚‰ãªã„ã‹ã‚‚知れã¾ã›ã‚“ãŒã€ã“ã‚Œã ã‘ã§ã‚‚ç°¡å˜ãªäººå·¥ç„¡è„³ãŒã§ãã‚‹ã‚“ã§ã™ã
Djangoフレームワークをå‰æã«ã—ã¦ã„ã¾ã™ã€‚
ã‚ã¾ã‚Šã‚³ãƒ¼ãƒ‰ã¨ã—ã¦ã¯å‚考ã«ãªã‚‰ãªã„ã‹ã‚‚知れã¾ã›ã‚“ãŒã€ã“ã‚Œã ã‘ã§ã‚‚ç°¡å˜ãªäººå·¥ç„¡è„³ãŒã§ãã‚‹ã‚“ã§ã™ã
Expand |
Embed | Plain Text
Copy this code and paste it in your HTML
URL: http://www.team-lab.com/news/index.php?itemid=469
Comments
 Subscribe to comments
Subscribe to comments